
Using JavaScript has an impact on how Google crawls and indexes your site. Make sure your use of JavaScript isn’t getting in the way of users finding your website via search engines.
JavaScript and SEO didn't always go well together. Search engine bots, including the Googlebot, couldn't crawl Javascript, so were unable to see any content embedded with JavaScript. Now, Google and other search engines can crawl and render JavaScript. In this article, we show you how you can implement JavaScript to ensure that your SEO isn't affected.
Tests show that the amount of JavaScript crawled and rendered on different websites differs greatly. Using JavaScript is therefore always associated with a certain risk; that the crawlers do not crawl and index the content, meaning users will not find it in search engines. This shouldn't scare you away from JavaScript, but from am SEO perspective, there are many things you should watch out for.
BING restricts the rendering capabilities of its bots with respect to JavaScript, and does not necessarily support all the same JavaScript frameworks supported in the latest version of your browser. Therefore BING recommends using dynamic rendering. Google also advises webmasters with quickly changing JavaScript content to use dynamic rendering.
In this article, Andy Favell from searchenginewatch shows in this article how JavaScript extends the loading time of mobile websites.
If JavaScript is used in the form of a tracking code third party script, you should allow the code to load at the end asynchronously so that the page speed is not affected.
Google has been able to render JavaScript and CSS since 2015, and recommended at the time that no important site components, including those in JavaScript or CSS are excluded from crawling via the robots.txt. Google also indicated that it prefers the principle of progressive enhancement, an approach involving the successive improvement of HTML websites. However, JavaScript would still be crawled and rendered.
In October 2018, in a response on Reddit, John Mueller pointed out that JavaScript would become increasingly important in the coming years, and gives SEOs the tip to focus more on JavaScript SEO: "If you're keen on technical SEO, then past HTML you're going to need to understand JS more and more".
With JavaScript, this direct access is not possible. Firstly, the crawler must analyze the DOM (Document Object Model). The DOM's code is loaded and listed, and only when this is done can the website be rendered. Every browser does this automatically when surfing the web. If you want to test JavaScript, you can use so-called "headless browsers." This is a browser without a graphic user interface that is operated by a command line.
JavaScript is more complex than HTML. To realize what is most important for SEO, you should firstly try to understand how JavaScript works:
1. Initial Request: The browser and the search engine bot start a GET request for the HTML code of the website and its affiliated assets.
2. DOM rendering: The JS script site delivers the DOM (Document Object Model) to the browser or the bot. The document shows how the content will be formed on the website and what the connections are between the individual elements on the site. The browser renders this information and makes it visible and usable for the user.
3. IDOM load: While the target site is being processed, the browser triggers events that belong to the DOMContentLoaded. The initial HTML document is then loaded and stored. The browser or the bot is now ready to implement JavaScript elements.
4. JavaScript implementation: JavaScript elements can now change the contents or functions of the website without the HTML source code having to be changed, removed, or expanded.
5. Load Event: As soon as the resources and the JS resources dependent on these are loaded, the browser starts the load, and the site is finished.
6. Post Load Events: After the JS site has been loaded, further content or functional elements can be changed or adapted by the user.
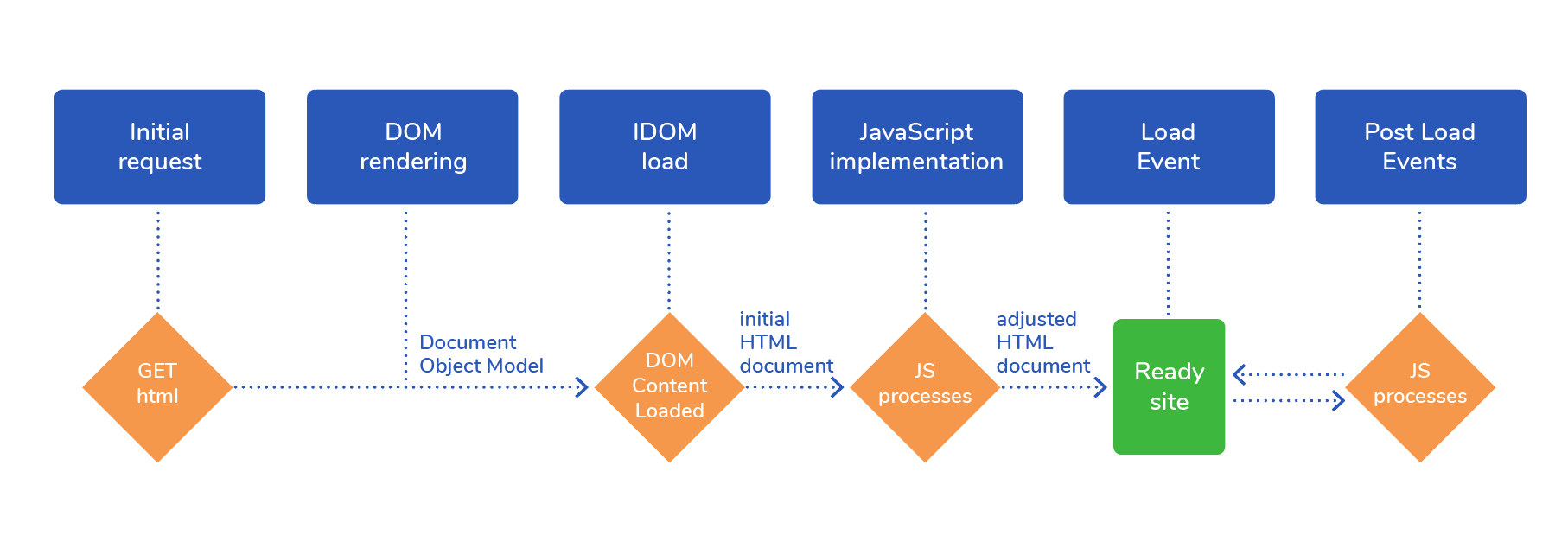
Figure 1: JavaScript process
Search engines such as Google use so-called headless browsers in order to simulate access to a traditional browser. In contrast to the "normal" browser, the headless browser calls up the code via the DOM to render a website from it. In this way, the Googlebot can, for example, check which elements JavaScript inserts in order to modify the HTML site. After the rendering, the Googlebot can analyze and index the rendered elements like an HTML source.
With JavaScript, there are two versions for crawlers, the pre-DOM HTML code and the rendered post-DOM HTML code.
Load events and user events can clearly influence your SEO. This is why:
The time frame of the DOMContentLoaded can be measured with the Google development tool:
If you use JavaScript on your website, Google can now render the elements after the load event quite well, and can finally read and index the snapshot like a traditional HTML site.
Most problems with JavaScript and SEO result from improper implementation. Many common SEO best practices can therefore also be used for JavaScript SEO. These are a few of the most common errors that can occur:
1. Indexable URLs: Every website requires unique and distinctive URLs so that the sites can be indexed at all. A pushState, as is created with JavaScript, however, does not generate a URL. Therefore, your JavaScript site also requires its own web document that can give a status code 200 OK as a server answer to a client or bot inquiry. Every product presented with JS (or each category of your website realized with JS) must therefore be equipped with a server-side URL so that your site can be indexed.
2. pushState errors: With the pushState method, JavaScript URLs can be changed. Therefore, you must absolutely ensure that the original URL is relayed with server-side support. Otherwise, you risk duplicate content.
3. Missing Metadata: With the use of JavaScript, many webmasters or SEO forget the basics and do not transfer meta data to the bot. However, the same SEO standards hold for JavaScript content as for HTML sites. So, think about title and meta description of ALT tags for images.
4. a href and img src: The Googlebot requires links that it can follow so that it can find further sites. Therefore, you should also provide links with href- or src-attributes in your JS documents.
5. Create unified versions: Through the rendering of JavaScript, preDOM and postDOM versions arise. Ensure that, if possible, no contradictions slip in and, for example, that canonical tags or paginations can be correctly interpreted. In this way, you will avoid cloaking.
6. Create access for all bots: Not all bots can deal with JavaScript like the Googlebot. It is therefore recommended to place title, meta information, and social tags in the HTML code.
7. Don't disable JS over robots.txt: Ensure that your JavaScript can also be crawled by the Googlebot. For this, the directories should not be excluded in the robots.txt.
8. Use a current sitemap: In order to show Google any possible changes in the JS contents, you should always keep the attribute "lastmod" current in your XML sitemap.
A JS website audit is primarily a manual inspection of individual elements.
To check your JavaScript, you can use the Google Developer Tools from Google Chrome as well as the Web Developer Expansion for Chrome.
1. Visual inspection
To get a feel for how a visitor will see a website, you should divide the content on the website into:
This way, you can narrow down the selection to elements that can be realized with JavaScript. You should be checking the JavaScript elements with the goal of making these elements crawl-able.
2. Check HTML code
With web developer tools, you can turn off CSS, JavaScript, and cookies. You can see what is missing on the site in the remaining code. These elements are controlled by JavaScript.
Then, you can control meta elements such as the title and website description. So that bots can index these elements, they must be accessible via the load event. In general, however, only Google can currently read these elements. It is therefore recommended to write title and meta tags in the HTMl code even with JS sites.
3. Check rendered HTML
Load the site with deactivated JavaScript and CSS anew. Finally, right-click on the site and choose "Examine element" in the Chrome menu. On the right side, another window will appear. Click on the HTML tag. With a right click, an options menu will appear. Choose "Copy External HTML" here. Finally, insert the code into an editor. This code can then be indexed by search engines such as Google.
You can also test JavaScript with the Google Search Console using the URL inspection tool or the mobile friendly test tool.
Further things to consider
1. prerender.io
prerender.io is an open-source software that optimizes the rendering of a JS site. With this, the site is cached after rendering and can be pulled up more quickly when accessed by a bot.
2. Brombone
This program downloads your website and renders it in a web browser, meaning you can easily check whether AJAX retrievals and JavaScript are functioning correctly. DOM changes can be tested in the same way. If the rendering is working, these sites are stored as HTML. If a crawler is accessing your site, you can allow the rendered JS sites to be issued by a proxy from Brombone. In order to correctly implement the tool, you also require an XML sitemap.
3. ANGULAR JS
With Angular JS, HTML snapshots can be prerendered so that the Googlebot can more quickly grasp and index JS sites.
4. SEO.JS
With this program, JS code is likewise rendered as HTML and made crawl-able by Google. The program code is hereby transferred to your server. Having your own dashboard will help you to manage those of your JS elements and sites that have to be rendered. Moreover, the tool creates an XML sitemap with your JS sites.
With the old version of the Search Console, Google helps you check JS elements by rendering individual sites. The tool also shows potential crawling problems.
With isomorphic JavaScript, applications can be carried out on the part of the server or the client. Back-end and front-end thus share the same code. By implementing the missing rendering, JavaScript is less error-prone with regards to SEO.
7. Ryte
Many SEO tools are now able to crawl JavaScript to give users a more complete analysis of their sites. As of February 2019, the Ryte crawler is also able to render and crawl JavaScript and CSS using an optimized Chrome browser. It executes the JavaScript on each page for up to 30 seconds, so all elements that are triggered when the page is first loaded are rendered and crawled. You can find out more in this article.
JavaScript can enormously expand the functionality of your website. However, there are many things you need to take into account to ensure that JavaScript fits into your SEO strategy. Sometimes it make more sense to use progressive enhancement rather than building a site solely with JavaScript, especially when considering AMP or progressive web apps. You should also make the use of the tools available to help create, edit or check the JavaScript elements on your site.
Practice makes perfect!
Analyze your JavaScript files with Ryte for FREE
This article was first published in May 2017, and updated in July 2020
Published on 07/22/2020 by Olivia Willson.

After studying at King’s College London, Olivia moved to Munich, where she joined the Ryte team till 2021. She was previously in charge of product marketing and CRO, and also helped out with SEO and content marketing. When she's not working, you can usually find her outside, either running around a track, or hiking up a mountain.